Introduction
The Aim: Get the code off my laptop and onto the remote server with as little human interaction as possible.
The app in this case is a node api that records page view events from this website and then allows the me to aggregate the data to understand visitor behavior. There is a separate post if you are interested here.
What it's replacing
Previously this was hosted on AWS Lambda with RDS as the database backend but—for reasons I'll leave unspecified for now—I have moved this onto a basic Ubuntu VM on Digital Ocean that I manage myself.
There are a few major benefits to using AWS Lambda:
- Scalable: AWS Lambda allows the number of "servers" available to handle requests to scale automatically from zero to 100 as demand ebbs and flows (or even aggressively spikes). For this application's needs however a single server is plenty to deal with the amounts of traffic expected. The bottleneck is most likely the database anyway and AWS can't autoscale that.
- Reliable: Another good reason to pick AWS Lambda is that Amazon's experienced and well financed ops team will be able to achieve a much better uptime than I could hope to manage alone. But this is just a side project, a little (or even a lot) of downtime is no big deal.
- Secure: Is my server up to date? Is SSH correctly configured? Are the firewall rules suitable restrictive? Hopefully, but AWS will be much less likely to miss something important. Ultimately though this project is really a toy and there won't be much to gain from getting access to it, as long as there is enough layers of security to get in the way of a "script-kiddie" I'm not too concerned.
These features aren't really useful for this project but the ability to upload a zip file of the code and have it automatically deploy onto the servers was great. With a side project where I may only spend an hour or two at a time I don't want to waste that moving files around and restarting services over SSH. With that in mind I have looked to build a system where a simple push to git can trigger the app to be build, packaged up and pushed to the remote server to be deployed automatically without any need to SSH into the server itself.
Step 1: Creating a package
The first step is to build the app. This is done by the CI system whenever a commit is pushed to master. This is very similar to how I used to deploy updates to Lambda (there is a old post on that here) but I'll point out the changes.
- Run npm install
The first thing to do is build the app. In this case it's as simple as installing the dependencies with npm.
- Record the version
To keep track of what version I then write a version.js file to the directory. This wasn't required before but it helps make it simple for the server to check which version it's currently running. I use the current commit hash as a version code simply because it already exists but any unique code will work.
module.exports = { "hash": "e02371ab6db3a60c3f9ead35e36187c91155b5a1", "msg": "Run a test deploy", "date": "Saturday, 18 Jan 2020 13:06:43 +0000" };
- Zip into a tar file
One change to note here is that Lambda only supports old fashioned zip files, as we are building our own system we can use the latest and greatest compression technology! But I actually went with tar.gz which was apparently invented in 1992. The tar's filename is the commit hash so we know which version it's for.
tar -czvf ./build/$HASH.tar.gz ./src
-
Upload to S3
Next we need to store these packaged tar files somewhere. I went with putting this into a simple S3 bucket. It might seem odd to go through all this trouble to move the app off AWS Lambda then add S3 as a dependency for the new system but it's cheap, reliable and I already know how it works so it was an obvious choice.
aws s3 cp ./build/$HASH.tar.gz s3://$PACKAGE_BUCKET/$HASH.tar.gz
-
Update version.json on S3
A record of which version is the most recent version is stored in a JSON file which is also on S3. This is what the server will check to see if it needs to update.
{ "hash": "e02371ab6db3a60c3f9ead35e36187c91155b5a1", "msg": "Run a test deploy", "date": "Saturday, 18 Jan 2020 13:06:43 +0000" };
-
Tell the server we have updated
The server will check periodically for any updates but to speed things up we can also tell it to check for updates now via a management API.
Once that is done the CI's job is now finished. Now we just wait for the server to do it's thing.
Updating the server
- Check for updates
Periodically (or when told about an update) fetch version.json and check if there is a new package availble.
// Get latest version hash from s3 var latestHash = JSON.parse(await request.get(task.versionFileUrl)).hash; // Check what version we have installed var installedHash = require(task.appDirectory + '/version.js').hash; // If we don't have the latest version trigger an update if(installedHash !== latestHash) { runUpdate(task); }
- Download off S3
aws s3 cp s3://$PACKAGE_BUCKET/$LATEST_HASH.tar.gz ./builds/nodeapi/$LATEST_HASH.tar.gz'
- Extract
tar -C ./builds/nodeapi/$LATEST_HASH/ -zxvf ./builds/nodeapi/$LATEST_HASH.tar.gz
- Move into place
rm -r /apps/nodeapi mv ./builds/nodeapi/$LATEST_HASH /apps/nodeapi
- Restart service
systemctl restart nodeapi
If it has updated:
Conclusion
Overall this works even better than I expected. Simply push to the remote git server and it automatically tests, builds and deploys everything with no human interaction at all within a couple of minutes.
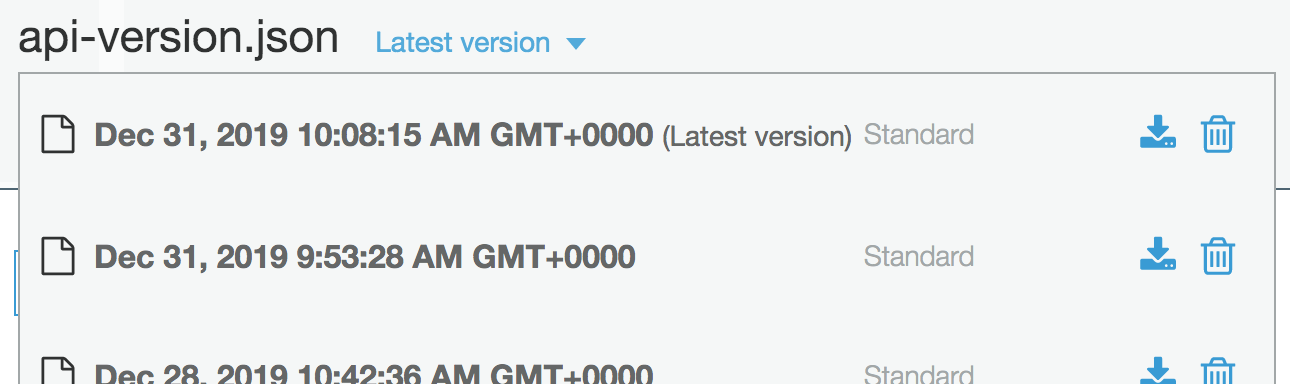
Reverting a bad version is quick and easy too. S3 supports versioned files so there is no need for any complex rollback code. The version history of the version.json file gives a full record of when each new deploy went out and reverting to an old version is enough to make the sever re-deploy the old package.